
原文链接:karpathy / llm-wiki.md(GitHub Gist,已获 5000+ Star)
最近,前 OpenAI 联合创始人、前特斯拉 AI 负责人 Andrej Karpathy 发布了一个 GitHub Gist,短短几天内获得了 5000+ Star 和 1200+ Fork,在 AI 圈引发了巨大共鸣。
他提出了一个极其敏锐的洞察:绝大多数人使用 LLM(大语言模型)的方式都错了。 我们总是把大模型当成一个"超级搜索引擎"或"高级聊天机器人",问完就走,知识毫无沉淀。
针对这个问题,Karpathy 分享了一个全新的工作流:LLM Wiki。核心思路是让大模型像一个不知疲倦的"知识工程师",帮你持续维护一个会复利增长的个人知识库。
这篇文章,我们将深度拆解 Karpathy 的这套"Idea File",并教你如何利用现成的工具(如 Obsidian、Claude Code 等)把这套理念真正落地。
一、痛点:为什么传统的 RAG 模式失效了?
我们目前处理长文档和知识库,最常用的方式是 RAG(检索增强生成),比如 NotebookLM 或 ChatGPT 的文件上传功能。
你上传一堆文件,提问时,系统会检索相关的片段(Chunks),然后大模型根据这些片段生成答案。
Karpathy 一针见血地指出了这种模式的致命缺陷:没有知识积累。
大模型每次都在"从零开始"重新发现知识。如果你问一个需要综合 5 篇文档的复杂问题,它每次都得重新找碎片、重新拼凑。一旦对话结束,那些极具价值的综合分析、对比表格就随风消散了。知识并没有被沉淀下来。
二、破局:Wiki 大于 RAG,让知识复利增长
Karpathy 的解决方案是:不要让 LLM 每次都在查询时去翻原始文档,而是让它增量地构建和维护一个持久的 Wiki。
这个 Wiki 是一个结构化的、相互链接的 Markdown 文件集合。

当你添加一个新资料时,LLM 不是简单地建立索引,而是:
- 阅读它,提取关键信息。
- 将新信息整合到现有的 Wiki 中。
- 更新相关的实体页面(Entity Pages)和主题摘要。
- 标注新数据与旧结论的矛盾之处。
知识只被编译一次,然后持续保持最新状态。 交叉引用已经建立,矛盾已经被标记。每一次新资料的加入,每一次有价值的提问,都在让这个 Wiki 变得更加丰富。
正如 Karpathy 所说:
“The wiki is a persistent, compounding artifact. The cross-references are already there. The contradictions have already been flagged. The synthesis already reflects everything you’ve read. The wiki keeps getting richer with every source you add and every question you ask.”
(Wiki 是一个持久的、复利增长的资产。交叉引用已经在那里了。矛盾已经被标记了。综合分析已经反映了你读过的一切。随着你添加的每一个来源和提出的每一个问题,Wiki 都在变得更加丰富。)
三、架构:LLM Wiki 的三层设计
在这个系统中,你是负责找资料和提问的"产品经理",而 LLM 是负责所有脏活累活的"程序员"。整个系统分为清晰的三层:
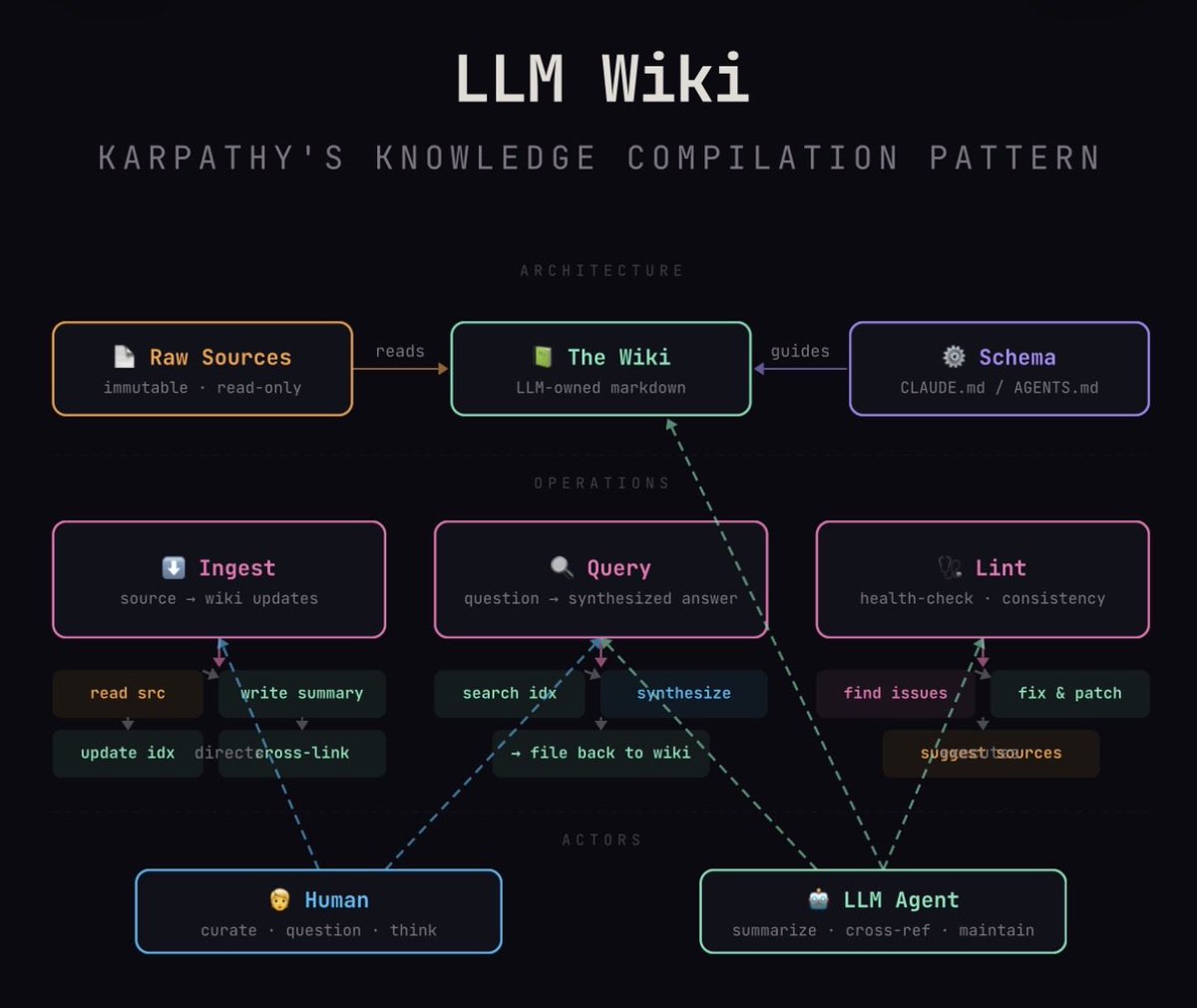
第一层:Raw Sources(原始资料层)
这是你的资料库,包含文章、论文、PDF、图片等。这一层是不可变的(Immutable),LLM 只读不写。这是你的"真理之源"。
第二层:The Wiki(知识库层)
这是 LLM 生成的 Markdown 文件目录。包含摘要、概念解析、对比分析等。这一层完全由 LLM 拥有和维护。你负责读,LLM 负责写。
第三层:The Schema(规则配置层)
这是一个核心配置文件(例如 CLAUDE.md 或 AGENTS.md)。它告诉 LLM 这个 Wiki 应该如何组织、遵循什么约定、以及处理新资料的 SOP(标准作业程序)。正是这个文件,让 LLM 从一个普通的聊天机器人,变成了一个纪律严明的 Wiki 维护者。
| 层级 | 名称 | 谁来写 | 作用 |
|---|---|---|---|
| 第一层 | Raw Sources | 你 | 原始资料,不可修改的真理之源 |
| 第二层 | The Wiki | LLM | 结构化知识库,Markdown 文件集合 |
| 第三层 | The Schema | 你(初始)+ LLM(迭代) | 规则配置,告诉 LLM 如何工作 |
四、实操:三个核心操作,让 Wiki 运转起来
Karpathy 总结了日常维护这个系统的三个核心操作:
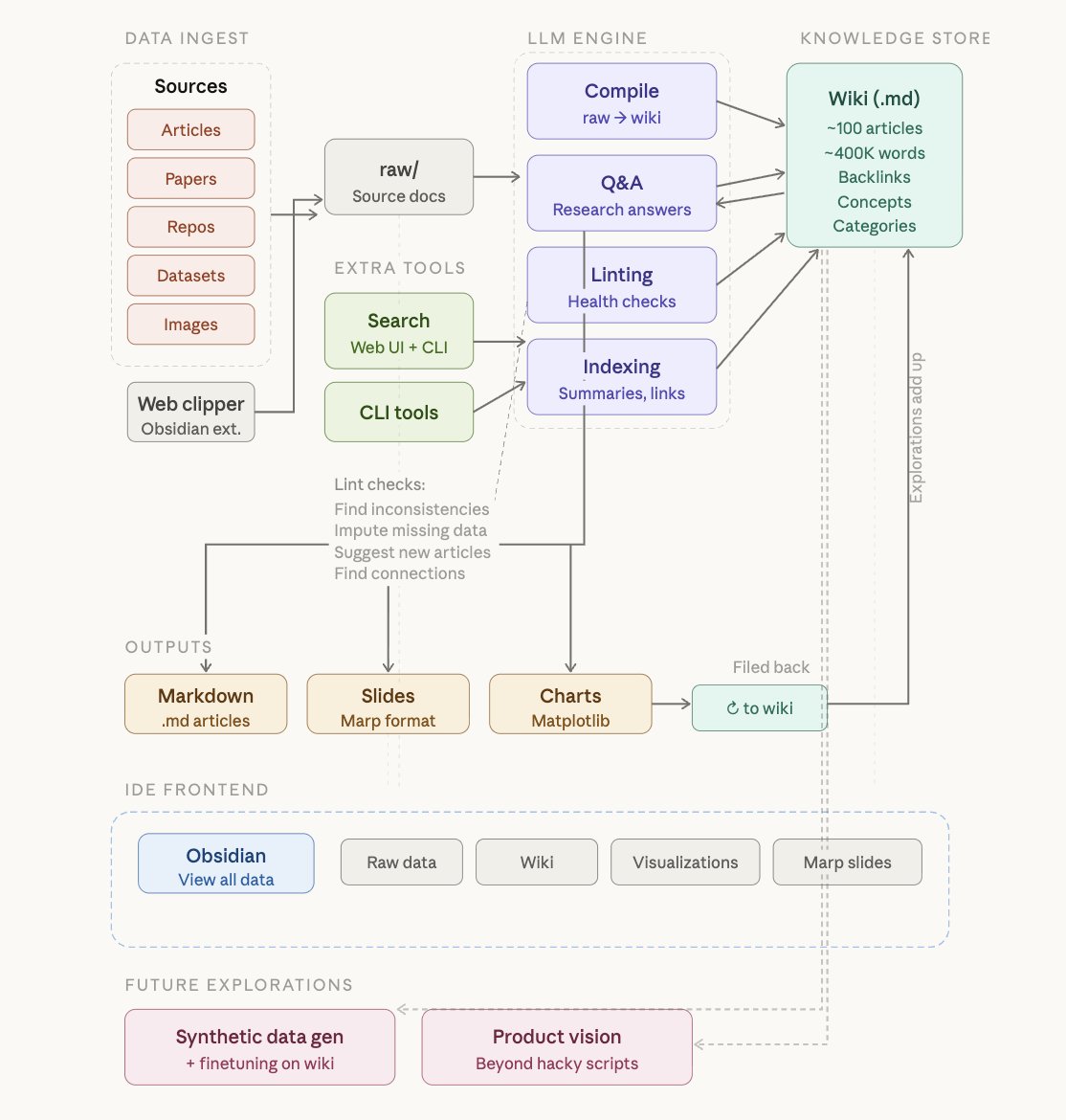
操作 1:Ingest(录入新资料)
你把一篇新文章丢进 Raw Sources,然后让 LLM 处理。LLM 会阅读文章,写一篇摘要放入 Wiki,更新总目录(index.md),并顺藤摸瓜地更新所有相关的概念页面。
一个新来源可能会触发 10-15 个 Markdown 文件的联动更新。
Karpathy 个人的习惯是每次只录入一个来源,这样可以实时查看摘要、检查更新,并引导 LLM 重点关注什么。但你也可以批量录入,让 LLM 自动处理。
操作 2:Query(提问与沉淀)
你向 Wiki 提问,LLM 会搜索相关页面并综合出答案。
这里有一个极其关键的洞察:好的答案应该被回存到 Wiki 中作为新页面。你让大模型做的一个深度对比表格、一个复杂的关联分析,都应该固化下来,成为知识库的一部分。
你的探索,会像录入新资料一样,持续地为知识库复利。
操作 3:Lint(定期体检)
定期让 LLM 对整个 Wiki 进行"健康检查"。找出:
- 相互矛盾的页面
- 没有外部链接的"孤岛页面"
- 过时的结论(被新来源推翻的旧观点)
- 数据空白(可以通过网络搜索填补的信息缺口)
大模型甚至能主动建议你接下来应该去研究什么新课题。
此外,系统中还有两个特殊的导航文件:
index.md:内容目录,按类别组织所有页面,LLM 每次录入都会更新它。在中等规模(约 100 个来源、数百个页面)时,这个文件就足以让 LLM 高效导航,完全不需要向量数据库。log.md:操作日志,按时间线记录所有的 Ingest、Query 和 Lint 操作,方便你追踪知识库的演进。
五、工具栈:你需要什么来落地?
Karpathy 强调,他分享的是一个"Idea File"(理念文件),而不是特定的代码。在 Agent 时代,你只需要把这个理念喂给你的 AI,它就能帮你搭建专属系统。
但他自己也分享了他目前使用的工具栈,我们来逐一介绍:
工具 1:Obsidian(作为 Wiki 的 IDE)
Obsidian 是目前最强大的本地 Markdown 知识库软件,完全免费,数据存储在本地。
在 Karpathy 的工作流中,Obsidian 是 IDE,LLM 是程序员,Wiki 是代码库。 你可以一边在终端运行 LLM Agent,一边在 Obsidian 里实时查看 Markdown 文件的更新。
Obsidian 的**图谱视图(Graph View)**是查看知识库结构的绝佳工具——你可以直观地看到各个 Wiki 页面之间的链接关系,随着知识库的增长,这张图会越来越密集。
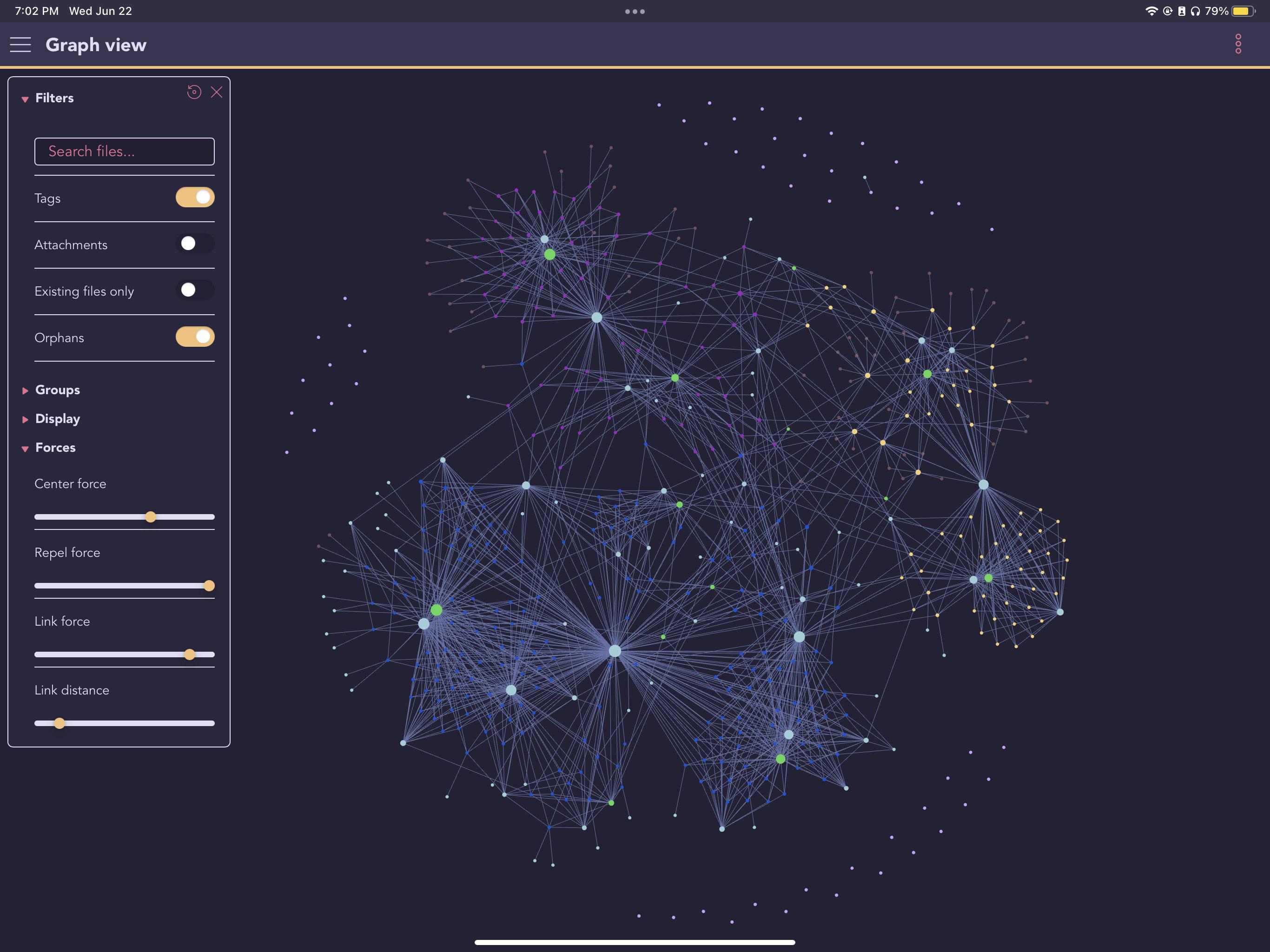
下载地址: obsidian.md(免费,支持 Windows/Mac/Linux/iOS/Android)
工具 2:Obsidian Web Clipper(网页剪藏,快速扩充原始资料)
这是 Obsidian 官方出品的浏览器插件,可以一键将网页文章转化为干净的 Markdown 格式,并直接保存到你的本地 Obsidian 目录中。
非常适合快速扩充你的 Raw Sources。看到一篇好文章,一键剪藏,LLM 稍后处理。
安装方式: 在 obsidian.md/clipper 页面点击"Add to Chrome"即可。
另外,Karpathy 还分享了一个小技巧:在 Obsidian 设置中,将"附件文件夹路径"设置为固定目录(如 raw/assets/),然后绑定一个快捷键(如 Ctrl+Shift+D)来"下载当前文件的附件"。这样剪藏文章时,所有图片也会一并下载到本地,让 LLM 可以直接读取图片内容。
工具 3:驱动 Wiki 的大脑(Claude Code / VS Code Copilot 等)
你需要一个能够在本地读取和修改文件的 LLM Agent。目前市面上有多种优秀的工具可以胜任:
选项 A:Claude Code(Anthropic 官方终端 Agent)
它可以在终端中直接运行,拥有修改本地文件的权限。非常适合喜欢命令行操作的极客。
# 安装并启动
curl -fsSL https://claude.ai/install.sh | bash
cd ~/my-wiki
claude
选项 B:VS Code + GitHub Copilot Agent Mode(最适合大众)
如果你更习惯图形界面,VS Code 结合最新的 GitHub Copilot Agent Mode 是完美的替代方案。它能直接读取你的工作区文件,并自动编辑、保存。
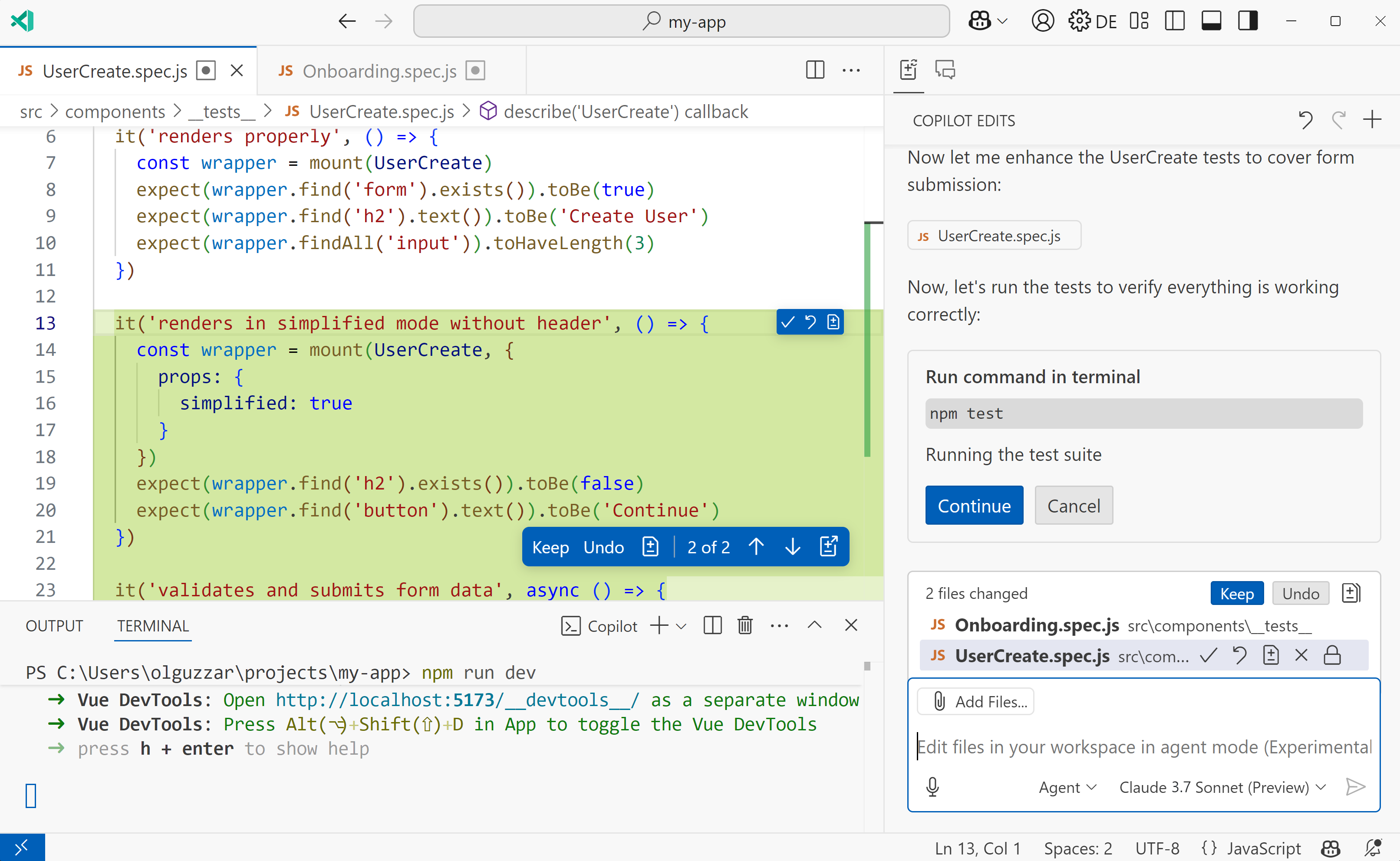
- 如何配置:在 VS Code 中安装 GitHub Copilot 插件,打开 Copilot Edits 面板,将模式切换为 Agent。
- 工作流:在项目根目录创建一个
AGENTS.md(类似于 Claude 的CLAUDE.md)作为 Schema 文件。然后直接在聊天框中让 Copilot 读取raw/目录下的新资料并更新 Wiki。
无论你使用哪种工具,启动后的第一步都是把 Karpathy 的 Gist 原文复制给它,告诉它:
“请根据这个理念,在当前目录下为我建立一个关于 [你的研究主题] 的 LLM Wiki,并生成配置文件(CLAUDE.md 或 AGENTS.md)。”
Agent 会自动创建目录结构、生成 Schema 文件,并开始处理你的第一批资料。
工具 4:qmd(进阶搜索,可选)
当 Wiki 规模中等时(几百个页面),LLM 依赖 index.md 就足够了。但当 Wiki 变得非常庞大时,你可能需要一个本地搜索引擎。
开源工具 qmd(Quick Markdown Search)是 Karpathy 推荐的选择。它是一个用 Rust 编写的高性能本地搜索引擎,支持:
- BM25 全文搜索
- 向量语义搜索
- 混合搜索(BM25 + 向量 + LLM 查询扩展)
- MCP 服务器模式:可以直接被 Claude Desktop 等工具调用
安装方式:
# 克隆并编译
git clone https://github.com/tidyinfo/qmd
cd qmd
cargo build --release
# 添加你的 Wiki 目录
qmd add ~/my-wiki
# 搜索
qmd search "你的查询关键词"
# 启动 MCP 服务器(供 Claude Desktop 调用)
qmd mcp
六、适用场景:你的 Wiki 可以用来做什么?
Karpathy 在原文中列举了几个典型场景:
| 场景 | 描述 |
|---|---|
| 个人成长 | 追踪自己的目标、健康、心理状态,随时间建立关于自己的结构化画像 |
| 深度研究 | 在某个课题上持续数周或数月,阅读论文、文章,增量构建综合性 Wiki |
| 读书笔记 | 逐章录入,建立人物、主题、情节线索的关联页面,像粉丝 Wiki 一样详尽 |
| 商业分析 | 竞品分析、尽职调查、差旅规划、课程笔记,任何需要随时间积累知识的场景 |
| 团队知识库 | 由 LLM 维护的内部 Wiki,喂入 Slack 消息、会议记录、项目文档,LLM 负责所有更新 |
七、结语:做知识的包工头,而不是搬砖工
维护知识库最痛苦的从来不是阅读和思考,而是那些繁琐的"簿记工作":更新交叉引用、修改双向链接、梳理分类标签。这也是为什么大多数人的笔记软件最后都变成了"资料坟场"。
LLM 永远不会觉得无聊,它能在一秒钟内准确无误地更新 15 个相关文件。
正如 Karpathy 所说:
“You never (or rarely) write the wiki yourself — the LLM writes and maintains all of it. You’re in charge of sourcing, exploration, and asking the right questions. The LLM does all the grunt work.”
(你永远不需要(或很少需要)自己写 Wiki——LLM 负责写和维护所有内容。你负责找资料、探索方向、提出好问题。LLM 负责所有脏活累活。)
这不仅是一个工具的升级,更是我们使用 AI 思维方式的根本转变。不要再做一次性的信息消耗者,开始建立你自己的复利知识资产吧!
参考资料:
[1] Karpathy’s LLM Wiki Gist: https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f
[2] Karpathy’s LLM Wiki: The Complete Guide to His Idea File: https://antigravity.codes/blog/karpathy-llm-wiki-idea-file
[3] Obsidian 官网: https://obsidian.md
[4] Claude Code 文档: https://docs.anthropic.com/en/docs/claude-code/overview
[5] qmd 工具: https://github.com/tidyinfo/qmd