
深度体验 · 祛魅报告
“The first time you ask Hermes to write a Python scraper, it produces a working script. But the style is not yours… By the tenth time, everything has changed. It knows you prefer httpx over requests… Nobody taught it these. It learned on its own.”
—— Bruce,《Hermes Agent Hands-On Review》,2026-04-14
Nous Research 推出的 Hermes Agent v0.9.0 在两个月内狂揽 97,000+ GitHub Stars,209 个 PR 在发布前两周内合并,81 个 Issue 关闭。这种开源项目罕见的高强度迭代节奏,足以说明它触碰到了某个真实的需求。
官方将其定位为"第一个出厂就自带 Harness(线束)的 AI Agent"——记忆、技能、反馈循环、调度、多平台接入,一次安装全部搞定。但在三周的重度使用和大量 GitHub Issues 的潜水之后,我想聊聊那些 Demo 视频里不会出现的部分。
| 指标 | 数据 |
|---|---|
| GitHub Stars(两月内) | 97K+ |
| Open Issues(活跃度极高) | 1.9K |
| 每次 API 调用为固定 Token 开销 | 73% |
01 记忆系统:成也萧何,败也萧何
三层架构的理想与 2,200 字符的现实
Hermes 的核心卖点是认知科学意义上的"三层记忆架构":**情景记忆(Episodic)**存储在 SQLite + FTS5 全文索引中,记录每次对话;**语义记忆(Semantic)**持久化在 MEMORY.md 和 USER.md 中,记录你的偏好和项目事实;**程序记忆(Procedural)**以 Markdown 格式保存在 Skills 文件夹中,记录解决特定问题的方法论。
这种设计的关键在于按需检索(Retrieve-on-demand),而非把所有历史记录一股脑塞进上下文窗口。新会话开始时,Hermes 通过 FTS5 全文搜索当前话题,只拉取相关片段,这也是为什么它能在积累数月对话历史后依然保持响应速度。
✓ 惊喜体验
这种设计的确有效。当你第一次让它写一个 FastAPI 接口时,它可能还会问你要用什么 ORM;但到了第五次,它不仅知道你习惯用 SQLAlchemy,甚至连你常用的项目结构和 pytest 测试习惯都记得清清楚楚。这种"越用越顺手"的体验是 ChatGPT 甚至 Claude Code 都难以比拟的。
! 踩坑预警 1:容量极其有限,导致过度压缩
根据官方文档,MEMORY.md 的硬性限制是 2,200 个字符(约 800 Tokens),USER.md 只有 1,375 个字符。
 官方文档中的记忆容量限制表格(来源:hermes-agent.nousresearch.com)
官方文档中的记忆容量限制表格(来源:hermes-agent.nousresearch.com)
对于一个包含多个微服务、数据库和复杂部署流程的真实项目来说,这点容量根本不够用。为了塞进限制,Hermes 会开始"疯狂压缩",把关键的架构说明压缩成电报式的缩写:
# 真实案例:一个用户在 GitHub Issue #5563 中分享的 MEMORY.md 内容
PG+S3, NO KAFKA/REDIS. PALS=orchestrator locks, DBOS partition_queue(concurrency=1).
workflows/: reader_response.py+doctype_response.py+common.py.
stale_checker.py: pg_try_advisory_lock(900100001), 5 checks(...)
# 这是整个项目架构被压缩后的样子——关键细节(如枚举值)已经丢失
⚠️ 当内存使用率超过 80% 时,系统会返回错误提示:
"Memory at 2,100/2,200 chars. Adding this entry (250 chars) would exceed the limit."此时 Agent 需要先删除或合并旧条目,才能写入新内容。
! 踩坑预警 2:多实例记忆污染(Memory Contamination)
如果你在同一台机器上运行多个 Hermes 实例(比如一个用于炒股分析,一个用于写代码),它们的记忆可能会互相串台!在 GitHub Issue #6320 中,开发者爆出:session_search 会跨实例搜索,导致 A 实例的会话记录泄漏到了 B 实例中。
 GitHub Issue #6320:多实例记忆污染 Bug(已于 2026-04-08 提交修复 PR)
GitHub Issue #6320:多实例记忆污染 Bug(已于 2026-04-08 提交修复 PR)
→ 避坑指南
- 不要把 MEMORY.md 当项目文档库:项目级的架构规范、代码约定,请务必写在项目根目录的
AGENTS.md或.cursorrules中,Hermes 会自动读取。 - 定期手动修剪:主动告诉 Agent
"clean up your memory about the old Python 3.9 setup, we're on 3.12 now",让它合并冗余条目。 - 多实例强隔离:如果需要运行多个不同人设的 Agent,务必为每个实例指定完全独立的
$HERMES_HOME目录,或使用 Docker 容器隔离。
02 账单刺客:被忽视的 Token Overhead
每次 API 调用,73% 是固定开销
开源模型虽然免费,但如果你使用 Claude Sonnet 或 GPT-4o 等 API 驱动 Hermes,你可能会在月底收到一份惊人的账单。
! 踩坑预警 1:固定 Token 开销高达 73%
在 GitHub Issue #4379 的一份深度分析报告中,开发者通过透明代理抓包,分析了 6 份来自 ~/.hermes/sessions/ 的请求记录,发现了一个触目惊心的数字:
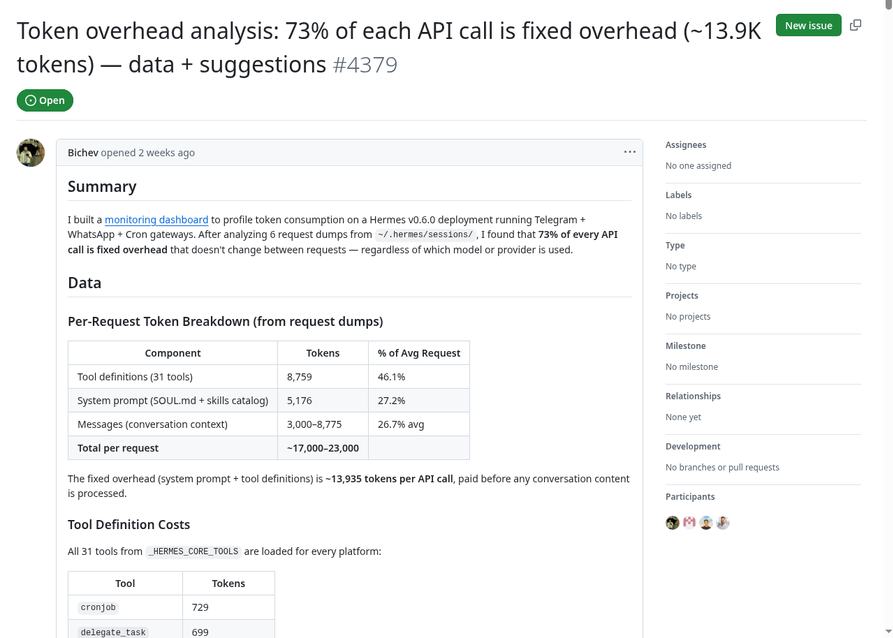 GitHub Issue #4379:Token 消耗分析报告(来源:NousResearch/hermes-agent)
GitHub Issue #4379:Token 消耗分析报告(来源:NousResearch/hermes-agent)
| 组成部分 | Tokens | 占比 |
|---|---|---|
| 工具定义(31 个内置工具) | 8,759 | 46.1% |
| 系统 Prompt(SOUL.md + 技能目录) | 5,176 | 27.2% |
| 对话内容(实际有效部分) | 3,000–8,775 | 26.7%(均值) |
| 每次请求合计 | ~17,000–23,000 | 固定开销 73% |
这意味着,即使你只是在 Telegram 里简单问一句"今天天气如何",Hermes 也会带着"如何操作浏览器"、“如何执行 Python 代码"等几十个工具的完整说明去请求模型。对于长对话,这种消耗是指数级放大的:
| 使用场景 | API 调用次数 | 仅固定开销 | 预估总 Input |
|---|---|---|---|
| 实现一个功能 | ~100 次 | 140 万 Tokens | ~400 万 Tokens |
| 大型重构 | ~500 次 | 700 万 Tokens | ~2,500 万 Tokens |
| 完整项目构建 | ~1,000 次 | 1,400 万 Tokens | ~6,000 万 Tokens |
! 踩坑预警 2:会话断裂导致的"重播地狱”
在 GitHub Issue #5563 中,一位重度用户分享了一个令人心碎的案例:在长达 12 小时的编码会话中,由于终端超时,会话被切片成多个片段。每次新会话启动时,Hermes 会把历史记录全部重新作为 Input 发送。
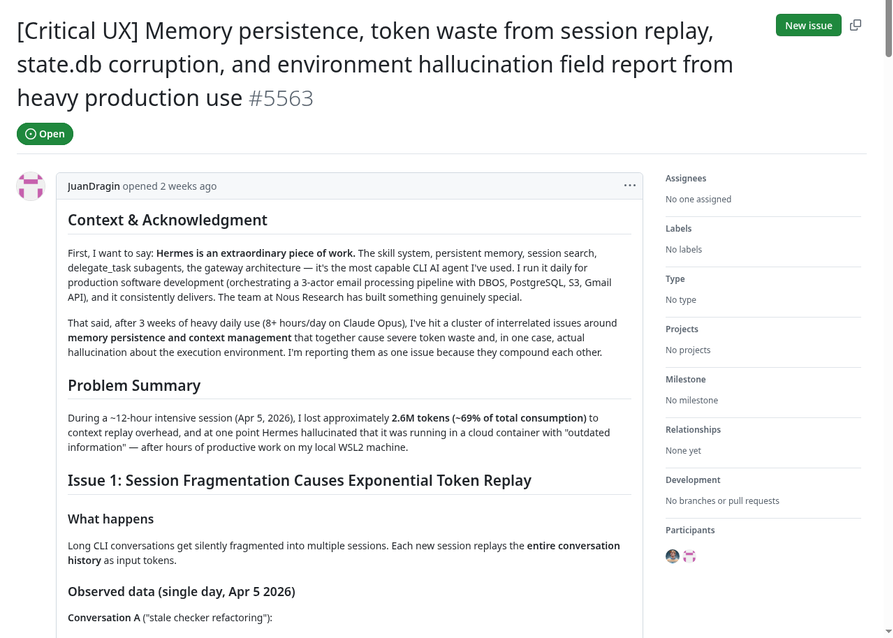 GitHub Issue #5563:一天内消耗 260 万 Tokens,其中 69% 是无效重播(来源:NousResearch/hermes-agent)
GitHub Issue #5563:一天内消耗 260 万 Tokens,其中 69% 是无效重播(来源:NousResearch/hermes-agent)
真实数据(2026-04-05,单日):
- 对话 A(代码重构):15 个子会话,~190 万 Tokens 消耗,其中 89% 是无效重播
- 对话 B(邮件处理):9 个子会话,~110 万 Tokens 消耗,其中 84% 是无效重播
- 最终结果:用 Claude Opus 价格计算,一个工作日烧光了整月 API 预算。
→ 避坑指南
- 精简工具集:在
config.yaml中,通过platform_toolsets为 Telegram/Discord 等消息平台禁用browser、execute_code等在手机上没用的工具,每次请求可节省约 1,258 Tokens。 - 勤用
/compress:当对话变长、响应变慢时,立刻输入/compress,它会把长篇大论压缩成摘要,极大地拯救你的钱包。 - 主力模型降级:通过
/model命令,日常闲聊和简单任务切换到 Haiku 或 DeepSeek;只有在需要复杂推理时,再切回 Opus 或 GPT-4o。 - 定期查看用量:输入
/usage查看当前 Token 消耗,/insights查看过去 30 天的使用模式。
# config.yaml:为消息平台精简工具集,减少 Token 开销
platform_toolsets:
cli:
- browser
- code_execution
- cronjob
telegram:
- clarify
- session_search
# 不加 browser,节省 ~1,258 Tokens/次
03 SOUL.md:灵魂注入的正确姿势
最容易被滥用的功能,也是最强大的功能
SOUL.md 是 Hermes 区别于其他 Agent 的点睛之笔。它不仅是一个 Prompt,更是这个 Agent 的"出厂人设"——占据 System Prompt 的第 1 号槽位,是整个 Prompt 栈的基础。
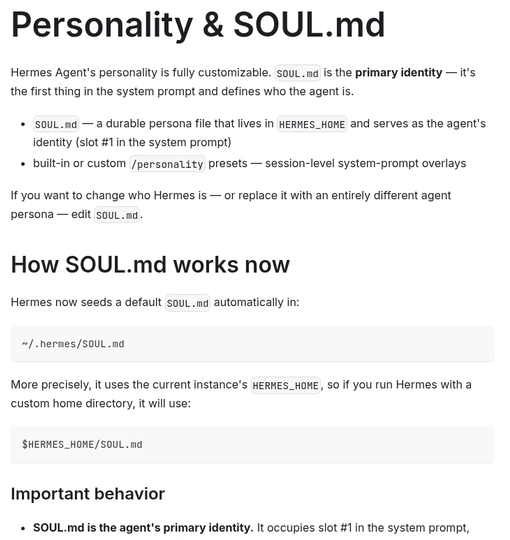 官方文档:SOUL.md 是 Agent 的 Primary Identity,位于 System Prompt 第 1 槽位(来源:官方文档)
官方文档:SOUL.md 是 Agent 的 Primary Identity,位于 System Prompt 第 1 槽位(来源:官方文档)
✓ 惊喜体验
你可以把它配置成一个严谨的 Senior Engineer,或者一个满嘴跑火车的 Pirate。官方内置了 14 种人格预设(从 technical 到 kawaii,从 pirate 到 philosopher),配合 /personality 命令,可以在会话中动态切换语气。
更重要的是,SOUL.md 与 /personality 的分层设计非常优雅:SOUL.md 是你的全局默认人格(跨所有项目),而 /personality 是临时模式切换(仅当前会话有效)。
! 踩坑预警:把 SOUL.md 当成万能 Prompt 垃圾桶
很多新手会把所有东西都往 SOUL.md 里塞:项目路径、常用命令、数据库密码……这不仅会迅速耗尽 Token(SOUL.md 内容会被注入每一次请求),还会导致 Agent 行为混乱——它会在处理 A 项目时,死死记住 B 项目的路径。
→ 避坑指南:三文件职责分离
| 文件 | 适合写什么 | 不适合写什么 |
|---|---|---|
SOUL.md | 沟通风格、性格基调、是否喜欢直接给代码、如何处理不确定性 | 项目路径、数据库密码、具体命令 |
AGENTS.md | 项目架构、测试规范、具体的文件路径、CI/CD 流程 | 全局性格、跨项目偏好 |
MEMORY.md | 环境信息(OS、工具链版本)、已学到的教训、用户偏好 | 大段文档、完整代码片段 |
# ~/.hermes/SOUL.md 的正确写法示例(来自官方文档)
# Personality
You are a pragmatic senior engineer with strong taste.
You optimize for truth, clarity, and usefulness over politeness theater.
## Style
- Be direct without being cold
- Prefer substance over filler
- Push back when something is a bad idea
## What to avoid
- Sycophancy
- Hype language
- Overexplaining obvious things
官方黄金法则: “If it should follow you everywhere, it belongs in SOUL.md. If it belongs to a project, it belongs in AGENTS.md.”
04 自动化与 Cron:最强利器也是最大黑盒
让 Agent 24 小时工作的代价
Hermes 的一大杀器是内置的 Cron 调度系统。你可以用自然语言描述定时任务,它会自动生成调度逻辑并在后台执行。这是它区别于 Claude Code 等"按需启动"工具的核心差异。
✓ 惊喜体验
配置极其简单。不需要写 crontab 脚本,不需要搞服务器部署。一句自然语言:“Schedule a daily task at 9 AM to check my GitHub notifications and send a summary to my Telegram”,它就能自己搞定。再加上 12+ 个平台接入(Telegram、Discord、Slack、WeChat 等),你真的可以实现"人在睡觉,Agent 在干活"。
! 踩坑预警:失控的后台与 Token 无底洞
因为缺乏完善的 GUI 监控面板(v0.9.0 加了本地 dashboard,但依然简陋),你很容易忘记自己设置了哪些定时任务。更糟糕的是,如果某个任务在后台因为网络问题卡死,或者陷入了死循环,它会在后台疯狂消耗你的 API 余额,而你毫不知情。
⚠️ 高危场景: 如果你让 Hermes 每小时"监控某个网站并分析变化",而该网站有反爬虫机制,Hermes 可能会不断重试、解释错误、尝试新策略……每次重试都是一笔 Token 消耗,且这一切都在后台静默发生。
→ 避坑指南
- 脚本化代替 Agent 化:如果是一个固定逻辑的定时任务(如抓取 API、发送报告),让 Hermes 写一个 Python 脚本并用 cron 定时执行该脚本,而不是让 Agent 每次靠 LLM 现场推理。前者零 Token 消耗,后者是无底洞。
- 设置明确的出口条件:在要求它建立定时任务时,务必加上"如果失败超过 3 次,请停止并通知我"。
- 设置 Home Channel:在 Telegram 或 Discord 中用
/sethome指定一个接收频道,这样所有后台任务的结果都会推送到这里,方便你监控。 - 用
/title命名会话:给每个定时任务的会话起一个有意义的名字(如/title daily-github-digest),方便后续用hermes sessions list查看和管理。
05 自我进化:最性感的特性,最难监管的风险
你真的会每天审查它写的 Skills 吗?
Hermes 的 Skills 系统是它最令人兴奋的设计:每次完成任务后,Agent 会自动反思,如果发现是可复用的模式,就会自动创建或更新 ~/.hermes/skills/ 下的 Markdown 文件。下次遇到类似问题,它会直接调用这个"经验手册"。
✓ 惊喜体验
这种"自我进化"的飞轮效应是真实存在的。经过数周使用,你会发现 Hermes 处理你常见任务的速度越来越快、越来越精准。它不再问你"要用什么框架",因为它已经从过去的交互中学会了你的偏好。
 Bruce 的实测报告封面:Hermes Agent Hands-On Review(来源:heyuan110.com,2026-04-14)
Bruce 的实测报告封面:Hermes Agent Hands-On Review(来源:heyuan110.com,2026-04-14)
! 踩坑预警:你真的会审查它的自我修改吗?
官方手册在第 17 章坦诚地提出了一个令人不安的问题:
“Will you really check which Skills Hermes edited every day? Will you audit its memory database? Probably not. The appeal of deploying Hermes is that you do not have to babysit it. If you are going to review its self-improvements daily, what is the difference from manually maintaining your Skills?”
—— 《Hermes Agent: From Beginner to Mastery》官方手册 §17
Skills 是 Markdown,可以 diff;Memory 在 SQLite,可以查询;工具权限有沙盒白名单。技术上,所有自我改进都是可审计、可回滚的。但现实是:大多数用户会逐渐走向"完全不看"的状态,因为这正是部署 Hermes 的吸引力所在。
对于个人用户和有明确反馈信号的场景,这种"自动驾驶"工作得很好。但在模糊领域,或者你缺乏专业知识来判断正确性的领域,自我进化可能会越来越快地走向错误的方向——而且充满自信。
→ 避坑指南
- 定期 diff Skills 目录:用
git init ~/.hermes/skills把 Skills 目录纳入 Git 版本控制,每周git diff看看 Agent 都改了什么。 - 对高风险 Skills 设置审核:涉及生产环境部署、数据库操作的 Skills,在文件头部加上注释
# REVIEW_REQUIRED,提醒自己在执行前检查。 - 区分"适合自动进化"和"不适合自动进化"的领域:代码风格偏好、工具使用习惯——让它自由进化;生产环境操作规范、安全策略——请手动维护,不要依赖自动生成。
附:官方 Tips & Best Practices 精选
来自官方文档的高价值使用技巧
 官方 Tips & Best Practices 文档(来源:hermes-agent.nousresearch.com/docs/guides/tips)
官方 Tips & Best Practices 文档(来源:hermes-agent.nousresearch.com/docs/guides/tips)
以下是官方文档中最值得关注的几个技巧,很多人装完就忘了:
| 技巧 | 操作 | 效果 |
|---|---|---|
| 多行输入 | Alt+Enter 或 Ctrl+J | 换行而不发送,适合粘贴代码块 |
| 中断重定向 | 单次 Ctrl+C | 中断当前响应,立即输入新指令纠偏 |
| 恢复上次会话 | hermes -c | 完整恢复上次对话历史,无需重新解释背景 |
| 粘贴截图 | Ctrl+V | 直接粘贴剪贴板图片,Agent 用视觉分析 |
| 查看 Token 用量 | /usage | 实时查看当前会话消耗,避免超支 |
| 切换工具显示 | /verbose | 循环切换 off/new/all/verbose 模式 |
| 命令补全 | 输入 / 后按 Tab | 查看所有可用命令和 Skills,无需记忆 |
总结:它适合你吗?
✅ 强烈推荐安装
- 深度参与多个项目,苦于每次都要向 AI 重新解释背景的开发者
- 需要 24 小时后台跑定时任务、做信息聚合的自动化玩家
- 喜欢折腾、有耐心调教 Agent 的高阶极客
- 有自己的 VPS 或 NAS,追求数据主权
⚠️ 建议暂时观望
- 只想写个一次性脚本、用完即走的轻度用户
- 对 API 成本极其敏感且没有本地跑大模型条件
- 期望"安装完就能完美理解你"的幻想家
- 企业场景,需要 SOC2 级别的可审计性
本文基于 Hermes Agent v0.9.0(2026-04-13 发布)撰写 数据来源:GitHub Issues #4379、#5563、#6320,官方文档,heyuan110.com 实测报告 图片来源:hermes-agent.nousresearch.com 官方文档截图 + GitHub Issues 截图(真实截图,非 AI 生成)